🤖AIシリコン・ウォーズ終焉か?NVIDIA GPU vs Google TPU、次世代AIチップの覇権バトルを徹底解剖!💻 #AI革命 #TPU #GPU #半導体 #士27 #1958NormanJouppiのGoogleTPU_令和IT史ざっくり解説AI編
🤖AIシリコン・ウォーズ終焉か?NVIDIA GPU vs Google TPU、次世代AIチップの覇権バトルを徹底解剖!💻 #AI革命 #TPU #GPU #半導体
AIの未来を左右する計算基盤の深淵へ!汎用性と特化、二つの哲学が織りなす壮大な技術競争の全貌と、私たちが生きる社会への影響を探ります。
📚 本書の目的と構成:なぜ今、AIチップの競争を知るべきなのか?
今、私たちの生活はAI(人工知能)技術によって劇的に変化しつつありますね。スマートフォンから医療、自動運転に至るまで、AIはあらゆる分野で革新をもたらしています。しかし、その裏側でAIを支える「計算の筋肉」とも言えるハードウェアが、熾烈な進化と競争を繰り広げていることをご存じでしょうか?
本書では、AIの進化を駆動する二大巨頭、Googleの独自開発チップ「TPU(Tensor Processing Unit)」と、長年AI計算のデファクトスタンダードとして君臨してきたNVIDIAの「GPU(Graphics Processing Unit)」に焦点を当てます。この二つのチップが持つ哲学、技術的な特徴、そしてそれぞれの市場戦略を深掘りし、AIハードウェア市場の現状と未来予測を分かりやすく解説することを目指します。
なぜGoogle TPUは誕生し、NVIDIA GPUとの競争を生んだのか?
Googleがなぜ自社で専用チップを開発するという大胆な決断を下したのか、その背景には何があったのでしょうか?そして、汎用性の高いGPUがAIのブレイクスルーを牽引してきた中で、なぜ特化型チップのTPUが新たな競争軸を打ち立てたのか。本書は、これらの疑問を解き明かし、読者の皆様がAI技術の根幹にある計算基盤の重要性を多角的に理解するための一助となることを目的としています。
本書の構成と読み方
本書は、AIハードウェアの歴史から最新技術、そして未来予測までを網羅した包括的な内容となっています。専門知識がない方にも理解しやすいよう、専門用語にはその都度解説を加え、豊富な具体例やコラムを交えながら、読者の皆様をAIチップの最前線へと誘います。各章は独立したテーマを持ちながらも、全体として一つの壮大な物語を紡ぐように構成されています。興味のある章から読み進めていただくことも可能です。
📖 要約(エグゼクティブサマリー):AI計算基盤の二大潮流
現代のAI技術、特に大規模言語モデル(LLM)の驚異的な進歩は、その裏側で進化を続ける高性能な計算ハードウェアによって支えられています。この分野における主要なプレイヤーは、NVIDIAが提供する汎用性の高いGPUと、Googleが自社サービスのために開発した特化型ASIC(特定用途向け集積回路)であるTPUです。
NVIDIA GPUは、元来グラフィックス処理のために開発された並列計算能力をAI学習に応用し、CUDAという強力なソフトウェアエコシステムを築き上げることで、市場を席巻してきました。特に、AI特化のTensor Coreを導入したHopperアーキテクチャのH100 GPUなどは、その性能と汎用性で広く利用されています。
一方、Google TPUは、膨大な社内AIワークロードの効率化を目指して設計されました。TPUは行列演算に特化したシストリックアレイ構造を持ち、レジスタアクセスを最小限に抑えることで、極めて高い電力効率とスループットを実現しています。 最新世代のTPUv5eやTrillium、そして開発中のIronwoodは、LLMの学習や推論においてGPUを上回るコスト効率や性能を提供し、GoogleのAIモデル「Gemini」の開発を強力に推進しています。
この競争は単なるチップ性能の優劣だけでなく、クラウドサービスの戦略、開発エコシステムの広さ、そしてAI技術の未来の方向性そのものに大きな影響を与えています。NVIDIAは汎用性と強力なエコシステムで盤石な地位を築きつつ、チップレット技術などで対抗。Googleは垂直統合戦略と特化型チップで効率性とスケーラビリティを追求しています。AMDなどの第三極もオープンソース戦略で市場の一角を狙う中、AI計算基盤の覇権争いは今後も目が離せません。
👨🔬 登場人物紹介:AIチップの巨人たち
ノーマン・P・ジョウピ(Norman P. Jouppi)
- 英語表記: Norman P. Jouppi
- 現地語表記: なし(アメリカ合衆国)
- 年齢: 2025年時点で約67歳(1958年生まれと推定)
- 解説: GoogleのVP(バイスプレジデント)兼エンジニアリングフェローであり、Google TPUの技術的な開発を主導した人物です。彼はMIPSプロセッサの初期アーキテクトの一人であり、Victim CacheやCACTIシミュレータといった現代のメモリ階層技術に多大な貢献をしました。 その設計思想は、RISCプロセッサの簡潔性と効率性、そしてメモリボトルネックへの深い理解に基づいています。TPUのシストリックアレイやソフトウェア制御バッファの設計は、彼の哲学が色濃く反映されたものです。 2013年にGoogleに入社し、わずか15ヶ月でTPUの設計からデータセンターへの導入までを成し遂げたという逸話もあります。
ジェンスン・ファン(Jensen Huang)
- 英語表記: Jensen Huang (Jen-Hsun Huang)
- 現地語表記: 黃仁勳(繁体字中国語)
- 年齢: 2025年時点で62歳(1963年2月17日生まれ)
- 解説: NVIDIAの共同創業者、社長兼CEOです。 グラフィックス処理ユニット(GPU)を世に送り出し、それを汎用計算、特にAIやHPC(高性能計算)の分野で革新的なプラットフォームへと発展させた立役者です。 CUDAという独自のソフトウェアエコシステムを構築し、NVIDIAをAI時代における半導体産業の巨人へと導きました。 そのカリスマ的なリーダーシップと先見の明は、多くの技術者や起業家から尊敬を集めています。
Google Gemini プロジェクトチーム
- 解説: Googleが開発した大規模マルチモーダルAIモデル「Gemini」の開発を担うチームです。Google DeepMindとGoogle Brainの専門知識を結集し、TPUの計算能力を最大限に活用することで、テキスト、画像、音声、動画など多様な情報を理解し、生成する能力を持つ最先端のAIモデルを実現しました。 彼らは、AIモデルの性能向上だけでなく、そのモデルを動かすハードウェアインフラの最適化にも深く関与し、モデルとチップの垂直統合戦略を推進しています。
📖 目次:AI計算基盤の全貌と未来
🌋 第一部 AI計算の「カンブリア爆発」と二つの哲学
1.1 汎用チップの限界とアクセラレータの必然
今から遡ること数年前、IT業界には「ムーアの法則の終焉」という暗い影が忍び寄っていました。半導体の集積度が指数関数的に向上し、性能が倍増し続けるという黄金時代が終わりを告げようとしていたのです。CPU(中央演算処理装置)の性能向上は鈍化し、同時に「電力の壁」という新たな課題が浮上しました。より多くの計算をするためには、より多くの電力が必要となり、それが発熱という形でボトルネックになったのです。
しかし、その頃、ひそかに「ディープラーニング(深層学習)」という新しい計算パラダイムが胎動していました。AIモデルが大規模化し、扱うデータ量が爆発的に増大するにつれて、従来のCPUだけでは到底処理しきれないほどの計算資源が必要になったのです。特に、大量の行列計算が伴うニューラルネットワークの学習や推論は、汎用性を重視するCPUのアーキテクチャとは相性が悪かったのです。例えるなら、スイスアーミーナイフのように何でもできるCPUが、特定のタスク(AI計算)においては専門の職人に劣る、という状況ですね。これが、AI計算のための専用アクセラレータが必然的に誕生する土壌となりました。
コラム:私が初めてAIに触れた時の衝撃
私が初めてディープラーニングの論文を読んだのは、まだ「AIブーム」という言葉が一般化する前のことでした。当時、画像認識の精度が飛躍的に向上しているのを見て、正直なところ「これは本当にすごいぞ…でも、こんな計算、どうやってるんだ?」と頭を抱えました。まさかその計算を支えるために、全く新しいチップが誕生し、それが世界を動かす競争になるとは、当時の私は想像もしていませんでしたね。技術の進化は、いつも私たちの想像の一歩先を行くものです。
1.2 二つの起源:汎用性と特化の道
AI計算のニーズが高まる中で、ハードウェアの世界では大きく分けて二つのアプローチが生まれます。
GPUの系譜:グラフィックスからGPGPUへ — 「何でもできる」汎用性の追求
一つは、NVIDIA GPUが辿った道です。GPUは元々、ビデオゲームなどのグラフィックス処理を高速化するために開発されました。画像を描画するためには、大量のピクセルに対して同時に同じ計算を行う必要があります。この「大量のデータを並列に処理する」というGPUの特性が、AIの行列演算と非常に相性が良いことが発見されました。NVIDIAは、このGPUを汎用計算(GPGPU:General-Purpose computing on Graphics Processing Units)に利用するための「CUDA(Compute Unified Device Architecture)」という開発プラットフォームを提供し、研究者や開発者がGPUの並列計算能力を容易に利用できるようにしました。 これにより、GPUはグラフィックスの世界から科学技術計算、そしてAI学習の分野へと、その活躍の場を大きく広げていったのです。CUDAエコシステムは、NVIDIAの揺るぎない市場優位性の大きな要因となっています。
TPUの系譜:データセンターの危機感から生まれたASIC — 「行列演算だけ」の特化の追求
もう一つは、Googleが選択した道、TPUの開発です。Googleは、検索、Googleフォト、Google翻訳など、自社の主要サービスでAIモデルを大規模に利用していました。2013年頃には、このままではAIワークロードのためにGoogleの全データセンターの2倍もの計算能力が必要になるという試算が出たほどです。 この危機感から、「AI計算に特化した専用チップ」を自社で開発するという、当時としては異例の決断を下します。
TPUの設計思想は、NVIDIA GPUの「汎用性」とは対極に位置する「ASIC(Application-Specific Integrated Circuit)」としての「徹底した特化」です。TPUは、ニューラルネットワークの中核である行列乗算・加算処理を高速化することに特化し、CPUやGPUに搭載されているような汎用的な機能を大胆に削ぎ落としました。これにより、電力効率と性能を極限まで高めることを目指したのです。 ノーマン・P・ジョウピ氏率いるチームは、わずか15ヶ月という驚異的なスピードで、TPUの設計からデータセンターへの導入までを成し遂げました。 これは、GoogleのAIファースト戦略の象徴とも言えるでしょう。
コラム:ASIC開発の裏側と「ジョウピのこだわり」
ASICの開発は、非常に時間とコストがかかることで知られています。汎用チップと異なり、一度設計したら変更が難しく、用途が限定されるため、ビジネス的なリスクも大きいものです。しかし、Googleは自社の膨大なAIワークロードがあるため、このリスクを取る価値があると判断しました。ノーマン・P・ジョウピ氏が語った「Never put off until runtime what you can do at compile time」(コンパイル時にできることを実行時まで決して遅らせるな)というMIPSプロジェクトの格言 は、TPUの設計哲学にも強く影響しています。キャッシュを最小限にし、データフローを予測可能にすることで、AI計算の効率を最大化する。まさに「職人技」のこだわりが詰まっているのです。
🧪 第二部 アーキテクチャ解剖:性能と効率の源泉
2.1 NVIDIA GPU:CUDAコアとTensor Core
NVIDIAのGPUは、数千もの「CUDAコア」と呼ばれるシンプルな演算器を搭載し、大量のデータを同時に処理する並列計算に長けています。 これは、もともとグラフィックスのピクセル計算に最適化されたものですが、ディープラーニングの行列演算も同様に高い並列性を要求するため、非常に効果的でした。
しかし、AIワークロードがさらに大規模化・複雑化するにつれて、NVIDIAはGPUをさらにAIに特化させる必要性を感じました。そこで、Voltaアーキテクチャ以降、GPUに「Tensor Core(テンサーコア)」を導入します。 Tensor Coreは、行列演算に特化した特殊な演算器であり、従来のCUDAコアよりもはるかに少ない命令で、より高いスループット(単位時間あたりの処理量)でAI計算を実行できます。例えば、HopperアーキテクチャのH100 GPUは、第4世代のTensor CoreとFP8精度をサポートするTransformer Engineを搭載し、GPT-3のような大規模言語モデルの学習を前世代より最大4倍高速化するとされています。 これは、汎用性を保ちつつ、AI特化の性能も追求するというNVIDIAの戦略を示しています。
GPUの強みは、その柔軟性と成熟したエコシステムにあります。CUDAは長年にわたり多くの研究者や開発者に利用され、豊富なライブラリ、フレームワーク、ツールが提供されています。これにより、様々な種類のAIモデルや計算タスクに容易に対応できる点が大きな魅力です。NVIDIAはハードウェアだけでなく、ソフトウェアプラットフォーム全体を「AIファウンドリ」として提供することで、市場における支配的な地位を確立しています。
2.2 Google TPU:シストリックアレイの魔術とメモリ戦略
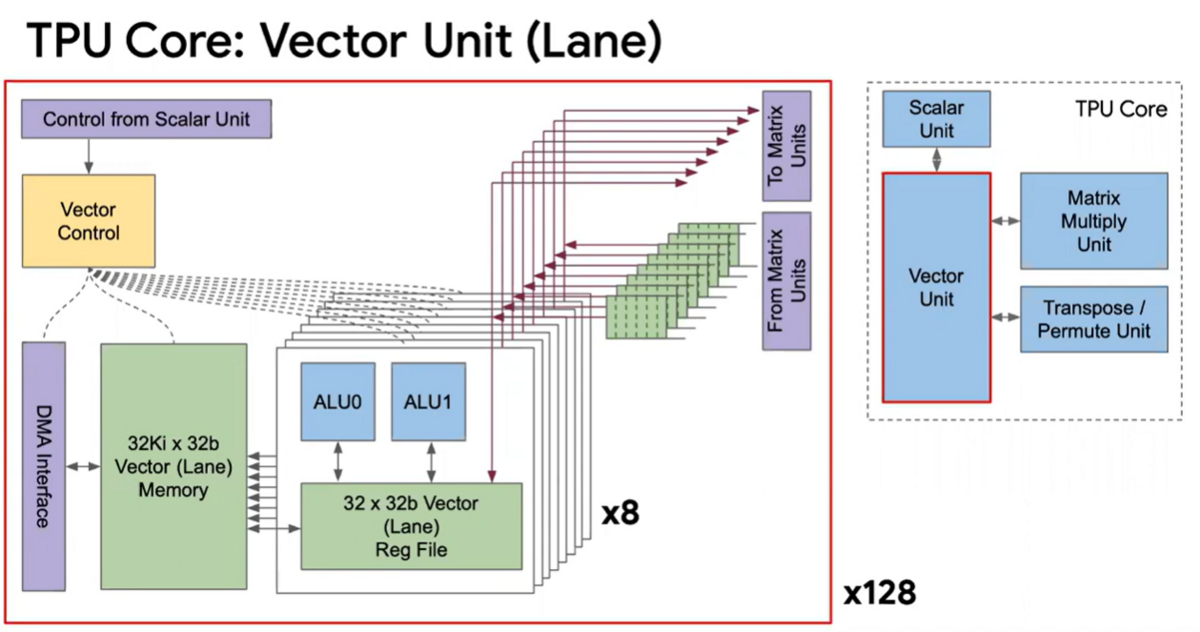
Google TPUは、NVIDIA GPUとは全く異なる思想で設計されたASICです。その心臓部にあるのが「シストリックアレイ(Systolic Array)」と呼ばれる特殊なアーキテクチャです。 TPUv1チップには、256×256の8ビット積和演算器が65,536個搭載されたMXU(行列乗算ユニット)が組み込まれていました。
シストリックアレイの最大の特長は、演算器(ALU)間のデータフローが極めて効率的であることです。通常のCPUやGPUでは、各演算結果がいちいちレジスタやキャッシュに書き戻され、次の演算のために再度読み込まれます。この「レジスタアクセス」が電力消費と遅延の大きな原因となります。しかし、TPUのシストリックアレイでは、各演算器が隣の演算器と直接接続されており、演算結果がまるで心臓から血液が送り出されるかのように、順次次の演算器へと直接流れていきます。 これにより、レジスタの読み書きが大幅に削減され、行列演算に特化することで、電力効率とスループットを劇的に向上させています。
また、TPUのメモリ戦略も独特です。従来のCPU/GPUが複雑なキャッシュ階層を用いるのに対し、TPUは「Unified Buffer(UB)」という24MBのSRAMを搭載し、ソフトウェアが明示的にデータを制御する方式を採用しています。 これは、ノーマン・P・ジョウピ氏が提唱した、コンパイル時にできる最適化を実行時まで遅らせないという哲学の具現化と言えるでしょう。 さらに、ニューラルネットワークのパラメータを32ビットや16ビットの浮動小数点数ではなく、8ビットの整数に「量子化(Quantization)」することで、メモリ使用量と計算リソースを大幅に節約し、電力効率をさらに高めています。
このように、TPUは「AIの行列演算だけ」という特定のドメインに徹底的に特化することで、他の汎用的な機能を大胆に排除し、結果としてチップサイズを小さく、製造コストを抑え、予測可能で高い性能を実現しています。 制御ロジックの占める割合がチップ全体のわずか2%に過ぎないという点からも、そのミニマル設計が伺えます。
2.3 性能・コスト・電力効率の定量比較
TPUとNVIDIA GPUの競争を理解するには、具体的な性能指標で比較することが不可欠です。Googleの発表によると、第一世代TPUは、同時代のCPUやGPUと比較して、ニューラルネットワークの推論において15〜30倍の性能向上と、30〜80倍の電力性能比を実現しました。
TPU vs NVIDIA GPU 性能・コスト・電力効率比較チャート
| 比較項目 | Google TPU (特化型ASIC) | NVIDIA GPU (汎用GPGPU) | コメント |
|---|---|---|---|
| 設計思想 | 行列演算に特化(シストリックアレイ) | 汎用並列計算(CUDAコア)+AI特化(Tensor Core) | TPUはAI専用に極限まで最適化、GPUは幅広い用途に対応しつつAI性能を強化。 |
| 電力効率 (性能/ワット) | 非常に高い(同世代GPU比30-80倍) | 高いが、汎用性の分TPUには劣る傾向 | データセンターの運用コスト(TCO)に直結するTPUの最大の強み。 |
| スループット (ピーク性能) | 非常に高い(特にAIワークロード) | 非常に高い(AI、HPC、グラフィックスなど) | TPUv1で92 Teraops/sec、TPUv5e podで100 Petaops/sec (INT8)。H100 GPUはFP8で3,958 TeraFLOPS (with sparsity)。 |
| 精度 | 8ビット整数演算が中心(量子化) | FP64, FP32, FP16, BF16, INT8, FP8など多様 | AI推論には低精度で十分なケースが多く、TPUはこれを活用。GPUは幅広い精度に対応。 |
| メモリ容量・帯域幅 | HBMメモリ、SparseCoreによるエンベディングサポート | HBM3メモリ、最大3.35TB/s (H100 SXM) | 大規模モデルに対応するため、両者とも高速・大容量メモリを重視。 |
| 接続性 (インターコネクト) | 光通信インターコネクト (OCS)、トーラス・ネットワーク | NVLink (最大900GB/s)、InfiniBand、PCIe Gen5 | TPU Podはデータセンター全体でのスケーリングに最適化。 |
| ソフトウェアエコシステム | JAX, XLAコンパイラ, PyTorch, TensorFlow (Google Cloudサービス経由) | CUDAエコシステム (広範なライブラリ、フレームワーク、開発者) | CUDAの「堀」は非常に強固。Googleは自社フレームワークとクラウドサービスで統合。 |
| 利用形態 | 主にGoogle Cloud上でのサービス利用 | オンプレミス、クラウド、HPCシステムなど多様な展開 | TPUは垂直統合モデル。GPUは汎用製品として広く販売。 |
特に、TPUv5eは、TPUv4と比較してLLMのファインチューニング性能が1ドルあたり最大1.9倍、推論スループットが1ドルあたり最大2.5倍、速度が最大1.7倍向上しています。 これは、AIワークロードに特化することで、コスト効率と性能の両面で大きな優位性を発揮していることを示しています。また、開発中のTPU7x (Ironwood)は、最大規模の学習と推論向けに設計されており、2025年第4四半期に一般提供が予定されています。
キークエスチョン:AIモデルの大規模化にハードウェアはどこまで追従できるか?
AIモデルのパラメータ数は、GPT-3の1,750億からさらに増え続け、兆単位の規模に達しようとしています。このような超大規模モデルの学習や推論には、膨大な計算資源とメモリ、そしてそれらを効率的につなぐ高速なネットワークが不可欠です。ハードウェアは、単に演算器を増やすだけでなく、省電力化、データ転送効率の向上、そしてチップレット技術のような新しい統合方法を駆使して、この爆発的な需要にどこまで応え続けられるかが問われています。
コラム:TPUの低コスト戦略とGoogleの「ケチ」精神
GoogleがTPUを開発した理由の一つに、コスト削減があります。当時のGoogleのデータセンターは、AIワークロードの増大で、このままでは膨大な電力とコストがかかり続けるという危機に瀕していました。TPUの設計者であるジョウピ氏は、TPUがCPUやGPUに比べて圧倒的に低コストで製造できる点を強調しています。 これは、チップサイズを最小化し、汎用機能を排除したミニマル設計によるものです。Googleが常に「効率」と「スケール」を重視する企業文化を持つからこそ、このような「ケチ」とも言える徹底したコスト最適化が、イノベーションの源泉となっているのかもしれませんね。
🔗 第三部 スケールアウトの覇権:システムとエコノミクス
3.1 究極の超大規模分散システム:TPU Pod
AIモデル、特に大規模言語モデル(LLM)の学習は、単一のチップだけでは不可能です。数千、数万ものチップを連携させ、膨大な計算を並列処理する必要があります。GoogleはTPUの設計において、この「スケーラビリティ」を最優先事項の一つとしました。その答えが「TPU Pod(TPUポッド)」という概念です。
TPU Podは、数百から数千ものTPUチップを専用の高速ネットワークで連結した、データセンター規模の「AIスーパーコンピューター」です。その鍵となるのが「光通信インターコネクト(OCS:Optical Circuit Switch)」と「トーラス・ネットワーク」という技術です。 OCSは、データセンター内のTPUチップ間の接続を動的に再構成できる光スイッチであり、データ転送のボトルネックを解消し、柔軟かつ効率的な通信を可能にします。トーラス・ネットワークは、各チップが隣接するチップと高速で接続される多次元の格子状ネットワークで、データ転送の遅延を最小限に抑え、大規模な分散学習においてほぼ線形に近いスケーリングを実現します。
TPU Podは、単にチップを多数集めただけでなく、データセンターのインフラ全体をAI計算に最適化する「システムとしての設計」が施されています。水冷システムや生体認証によるセキュリティまで統合されており、高い信頼性、可用性、セキュリティを提供します。 これにより、GoogleはGeminiのような世界最先端のAIモデルを効率的に開発・運用できる基盤を確立しているのです。
3.2 NVIDIAの対抗戦略:NVLinkとシステム製品化
NVIDIAもまた、大規模AIモデルの学習・推論には、チップ単体の性能だけでなく、それらを連携させるシステム全体の性能が重要であることを認識しています。そのためのNVIDIAの主要な技術が「NVLink」と、それを基盤とする「DGX/HGXシステム」です。
NVLinkは、GPU間の超高速直接接続技術であり、PCIeよりもはるかに高い帯域幅(H100では最大900GB/s)を提供します。 これにより、複数のGPUがあたかも一つの巨大なGPUであるかのように連携し、大規模なモデルを効率的に学習・推論することが可能になります。さらに、NVIDIAは「NVLink Switch」を導入することで、より多くのGPUを効率的に接続し、大規模クラスタの構築を容易にしています。
NVIDIAは、これらの技術を統合した「DGXシステム」や「HGXシステム」といったターンキーソリューション(すぐに使える完成されたシステム)として提供しています。これらは、AIワークロードに最適化されたハードウェアとソフトウェアを一体化しており、顧客は複雑なインフラ構築の手間なく、すぐにAI開発に着手できます。 NVIDIAは、チップの販売だけでなく、AIスーパーコンピューターを「製品」として提供することで、市場における優位性を維持し、顧客のNVIDIAエコシステムへのロックイン(囲い込み)を強化する戦略をとっています。
3.3 ソフトウェア戦争:CUDAの「堀」とROCmの挑戦
AIハードウェアの競争は、チップの性能だけでは決まりません。そのチップを動かす「ソフトウェア」が極めて重要です。この点で、NVIDIAは長年にわたり圧倒的な優位性を築いてきました。
NVIDIAの神話:CUDAエコシステムが市場支配を可能にする論理
NVIDIAの最大の強みは、そのGPGPUプログラミングプラットフォーム「CUDA」です。 CUDAは、開発者がGPUの並列計算能力をC++などの一般的なプログラミング言語から容易に利用できるようにするツールキット、ライブラリ、APIの集合体です。長年にわたるNVIDIAの投資により、CUDAは事実上の業界標準となり、膨大な数のAI研究者や開発者がCUDAベースのアプリケーションやフレームワーク(PyTorch、TensorFlowなど)を利用しています。この広範なCUDAエコシステムは、NVIDIA GPUから他のチップへの移行を困難にする「堀(Moat)」として機能し、NVIDIAの市場支配を盤石なものにしています。
Googleの応答:JAX、XLAコンパイラによるTPU最適化
Googleは、TPU向けに独自のソフトウェアスタックを構築しています。主要なAIフレームワークであるTensorFlow、PyTorch、JAXがTPUをサポートしており、特にXLAコンパイラは、これらのフレームワークで記述されたモデルをTPUのハードウェア特性に合わせて最適化する役割を担っています。 これにより、開発者は高レベルなコードを記述するだけで、TPUの高速な行列演算能力を最大限に引き出すことができます。Googleは自社のクラウドサービス(Google Cloud)を通じてTPUを提供し、ハードウェアとソフトウェア、そしてクラウドサービスを垂直統合することで、独自のAI開発エコシステムを構築しています。
AMDの挑戦:ROCmによるオープンソースプラットフォーム戦略と市場参入の可能性
NVIDIAのCUDA独占に対抗するため、AMDは「ROCm(Radeon Open Compute platform)」というオープンソースのGPGPUプラットフォームを推進しています。ROCmは、CUDAに代わる選択肢として、NVIDIA依存からの脱却を目指す企業や研究機関から注目されています。AMDは、Instinct GPUとEPYC CPUを組み合わせたフルスタックの半導体ポートフォリオを持ち、HPC(高性能計算)とAI市場における差別化を図る機会をうかがっています。 しかし、ROCmエコシステムはまだCUDAほど成熟しておらず、NVIDIAの長年の優位性を覆すには、さらなる開発者コミュニティの拡大と、性能・機能面での充実が課題となっています。
キークエスチョン:開発者がCUDA依存から脱却するために、ROCmは今後何を克服する必要があるか?
CUDAは単なるプログラミング言語ではなく、豊富なライブラリ、デバッガ、プロファイラ、そして何よりも巨大なユーザーコミュニティによって構成される強固なエコシステムです。ROCmが真の対抗馬となるには、CUDAと同等、あるいはそれ以上の開発体験を提供し、既存のCUDAコードベースからの移行を容易にするツールや、新たなAIモデル開発におけるROCmネイティブの優位性を示す必要があります。オープンソースであることは大きな魅力ですが、それだけではNVIDIAの牙城を崩すには不十分かもしれません。
コラム:ソフトウェアの壁は厚い!
ハードウェアがどんなに革新的でも、それを使いこなすソフトウェアがなければ宝の持ち腐れです。これは技術開発の永遠の課題ですね。特にAIのような急速に進化する分野では、ハードウェアの進化とソフトウェアの最適化が同時に進む必要があります。NVIDIAが築き上げたCUDAの「堀」は、まさにソフトウェアの力がハードウェアの市場支配を決定づける好例と言えるでしょう。この「ソフトウェアの壁」を越えることは、新規参入者にとって最も困難な挑戦なのです。
🔮 第四部 AI市場の未来地図と競争戦略
4.1 Gemini 3.0の衝撃とクラウドAI市場の行方
2025年11月19日(日本時間)、Googleは最新の生成AIモデル「Gemini 3」を発表しました。 このローンチは「Sim-shipping(Simultaneous Shipping=同時出荷)」という形で、Googleの検索、YouTube、クラウド、Waymoといったあらゆるプロダクト群に対して同時に展開されました。これは、GeminiがGoogleの文字通りすべてのプロダクトを貫く「スルーライン(一本の背骨)」として機能することを示唆しています。
Gemini 3.0の登場は、Googleの「AIファースト」戦略と、それを支えるTPUインフラが、世界最先端のAIモデル開発を効率的に支えていることを強力に証明しました。特に、モデルとインフラの垂直統合により、インフラ層の改善が最上位の製品層にまで「乗数効果(multiplicative effect)」として波及する強みが強調されています。
さらに、Gemini 3と共に展開された軽量・高性能モデル「Nano Banana Pro」は、情報を「圧縮」し、視覚的なインフォグラフィックに変換する能力を持つなど、Googleの「世界中の情報を整理し、アクセス可能にする」というミッションをAI時代において具現化するものです。 そして、「Vibe Coding」のような自然言語でAIにソフトウェア構築を指示する新しい開発スタイルは、プログラミングの民主化を促進し、人々の「潜在的創造性」を解放すると期待されています。
Googleのスンダー・ピチャイCEOは、長期的なビジョンとして2027年までに宇宙にデータセンターを建設する「Project Suncatcher」構想にも言及しており、未来の莫大なコンピューティング需要を見据えた壮大な挑戦を示しています。
Google独占の可能性:クラウドAI市場はGoogle独占に近づくのか?
Gemini 3.0はGoogle Cloudにとって強力な差別化要因となりますが、クラウドAI市場全体がGoogle一社に独占されると考えるのは早計でしょう。企業はベンダーロックインを避けるためにマルチクラウド戦略を採用する傾向があり、NVIDIAのCUDAエコシステムは依然として強固です。AWSやMicrosoft Azureも、独自のカスタムチップ開発やパートナーシップを通じて、Googleの垂直統合戦略に対抗しています。競争は今後も続き、多様な選択肢が提供されることになりそうです。
4.2 NVIDIAの対抗策とチップレット戦略
GoogleのTPUとGeminiの進化に対し、NVIDIAも手をこまねいているわけではありません。NVIDIAは、GPUアーキテクチャの継続的な進化と、ソフトウェアエコシステムのさらなる強化で対抗しています。
HopperアーキテクチャのH100 GPUは、前述の通りTensor CoreやTransformer Engineの強化により、大規模モデルの学習・推論性能を飛躍的に向上させました。 そして、次世代の「Blackwellアーキテクチャ」は、「新しい産業革命のエンジン」と称され、さらなる性能向上と効率化が期待されています。 Blackwellでは、複数の半導体ダイを組み合わせる「チップレット(Chiplet)」設計が導入されると予想されており、これにより製造コストの最適化や、より柔軟なプロセッサ構成が可能になります。
また、ジェンスン・ファンCEOは、NVIDIAを単なるハードウェアベンダーではなく、「AIファウンドリ」として位置づけ、ソフトウェア、サービス、プラットフォーム全体でAIエコシステムを構築するビジョンを描いています。Omniverseのような仮想世界プラットフォームへの投資もその一環であり、NVIDIAは多角的な戦略でAI時代の覇権を盤石にしようとしています。
4.3 新たな競合と市場の分断
NVIDIAとGoogleの二大巨頭の他に、AIハードウェア市場には新たなプレイヤーが続々と参入しています。AMDは、高性能なInstinct GPUとEPYC CPUを組み合わせ、オープンソースのROCmプラットフォームを武器に、NVIDIAの牙城を崩そうと試みています。IntelもGaudiなどのAIアクセラレータで市場に食い込もうとしています。
さらに、「推論特化チップ」という新たなニッチ市場も形成されつつあります。例えば、GroqやCerebrasのような企業は、特定のAIワークロード(特に推論)に特化したアクセラレータを開発し、超低遅延や超大規模モデル対応で差別化を図っています。これは、AIの利用が多様化するにつれて、汎用的なソリューションだけでは対応しきれない細分化されたニーズが生まれていることを示しています。
歴史的位置づけ:TPU vs NVIDIAの戦いは、メインフレームからPCへの移行、あるいはCISCからRISCへの移行に匹敵するか?
この問いは非常に興味深いですね。TPUとNVIDIA GPUの競争は、単なる技術的な優劣だけでなく、コンピューティングの根本的なパラダイムシフトを示唆している可能性があります。メインフレームからPC、あるいはCISCからRISCへの移行は、計算の中心が「汎用性と集中」から「分散と特化」へと移り変わる過程でした。
現在のAIハードウェアの動向も、汎用的なGPUがAIの初期を牽引したものの、AIモデルの特異な計算特性(大規模な行列演算、低精度演算の許容)が明らかになるにつれて、TPUのようなドメイン固有アーキテクチャ(DSA)が台頭するという流れです。これは、特定のワークロードに最適化されたハードウェアが、その分野で汎用ハードウェアを凌駕するという、歴史的な転換点に私たちが立ち会っている可能性を示唆しているのかもしれません。AIの時代は、再び「特化」が「汎用」に挑む、あるいは共存する新たなコンピューティングの夜明けとなるでしょう。
コラム:AIチップを巡る「外交」の重要性
AIチップは、もはや単なる技術製品ではありません。国家間の競争、サプライチェーンの安定性、そして経済安全保障の観点からも極めて重要な戦略物資となっています。米国や中国がAIチップ開発に巨額の投資を行い、輸出規制などの政策を打ち出しているのは、まさに「AIの覇権」が未来の国力に直結すると見ているからです。かつて石油が「黒い金」と呼ばれたように、AIチップは現代の「シリコンの金」と言えるのかもしれませんね。技術者だけでなく、政治家やエコノミストも、このチップ戦争の動向に目を凝らす必要があります。
🇯🇵 第五部 日本と世界への影響
5.1 日本への影響:技術主権とインフラ戦略
詳細を見る
日本のAIインフラは、現状、その多くをNVIDIA製GPUに依存していると言えるでしょう。国内の多くの研究機関や企業が、AI開発においてNVIDIAのハードウェアとCUDAエコシステムを活用しています。しかし、Google TPUやAMDのROCmのような選択肢の登場は、日本にとって新たな戦略的示唆を与えます。
国内企業・研究機関の戦略的示唆:
- NVIDIA依存からの脱却とリスク分散: 一つのベンダーに過度に依存することは、コスト高騰やサプライチェーンのリスクにつながる可能性があります。TPUやAMDのGPUの活用を検討することで、選択肢を広げ、価格交渉力を高めることができます。
- 特化型AIチップ開発の可能性: 日本には高い技術力を持つ半導体製造装置メーカーや材料メーカーがあります。TPUのようなドメイン固有アーキテクチャの開発は、日本の技術主権を確立し、世界市場で独自の存在感を示すチャンスとなり得ます。ただし、ASIC開発には巨額の投資と長期的な視点が必要であり、国家レベルでの戦略的な支援が不可欠です。
- クラウド利用の最適化: Google CloudのTPUを利用することで、自社で高価なGPUクラスタを構築・運用するコストと手間を削減し、AI開発に集中できます。特に、LLMのような大規模モデルの学習には、Googleの垂直統合されたTPU Podの効率性が大きなメリットとなるでしょう。しかし、データのセキュリティや主権に関する懸念も考慮に入れる必要があります。
日本のAIハードウェア開発の現状と課題:
現状、日本におけるAIチップの自社開発は、海外の巨大テック企業や半導体メーカーに比べて遅れをとっていると言わざるを得ません。過去にはスーパーコンピュータ「京」や「富岳」のような世界トップレベルの成果を上げてきましたが、AI特化型チップの分野では、設計、製造、そしてソフトウェアエコシステムのいずれにおいても、世界をリードするプレイヤーが不在です。
課題としては、以下の点が挙げられます。
- 投資規模の差: GoogleやNVIDIA、中国のAIチップ企業と比較して、日本のAIチップ開発への投資規模は小さい傾向にあります。
- 人材不足: 最先端の半導体設計者やAIソフトウェアエンジニアの育成・確保が喫緊の課題です。
- エコシステムの構築: 独自のチップを開発しても、それを使いこなすためのソフトウェアツールや開発者コミュニティがなければ普及しません。
海外競争力と連携可能性:
日本は、最先端のプロセス技術を持つTSMC(台湾積体電路製造)の工場誘致(熊本)や、Rapidusのような次世代半導体製造技術の開発を進めることで、製造面での強みを再構築しようとしています。これらの動きは、将来的に国内でAIチップを製造する基盤となり得ます。
同時に、日本は国際的な連携を強化し、欧米の主要企業や研究機関との協力関係を築くことも重要です。例えば、米国のAIチップスタートアップとの共同研究や、オープンソースのROCmエコシステムへの貢献を通じて、日本のプレゼンスを高めることができます。
キークエスチョン:日本はクラウド依存か自社開発か、どちらが望ましいか?
この問題は、一概にどちらか一方を選ぶべき、と断言できるものではありません。短期的には、Google CloudのTPUやNVIDIA GPUのような既存の高性能クラウドサービスを賢く利用し、AI開発のスピードを上げることが現実的です。これにより、AIモデルやアプリケーションの開発にリソースを集中できます。
一方で、長期的には、技術主権と経済安全保障の観点から、特定のAIチップに依存しすぎない体制を構築することが重要です。そのためには、大学や研究機関、そして企業が連携し、基礎研究から応用開発、人材育成に至るまで、戦略的な国家プロジェクトとしてAIチップの自社開発(または国際共同開発)を推進する必要があります。理想的には、クラウドの恩恵を受けつつ、戦略的に重要な分野では自社開発の可能性も追求する「ハイブリッド戦略」が望ましいと言えるでしょう。
5.2 今後望まれる研究
AIハードウェアの未来を切り拓くために、今後、特に以下の分野での研究が望まれます。
- ハードウェア最適化:LLM訓練における疎性(Sparsity)処理の効率化研究
大規模言語モデル(LLM)の計算において、その多くの部分が「疎(Sparse)」である(つまり、多くの重みがゼロに近い値を持つ)ことが知られています。この疎性を活用し、不要な計算をスキップすることで、電力効率と性能を大幅に向上させることが可能です。TPUのSparseCoreはその一例ですが、さらに進んだ疎性処理アルゴリズムと、それを効率的に実行できるハードウェアアーキテクチャの研究が不可欠です。 - ソフトウェア研究:CUDAからの脱却を支援するコンパイラ技術の開発
NVIDIAのCUDAエコシステムは強力ですが、ベンダーロックインのリスクもはらんでいます。異なるハードウェア(TPU、AMD GPU、Intelアクセラレータなど)上で高性能なAI計算を実現するための、より汎用性の高いコンパイラ技術やプログラミングモデルの研究が必要です。オープンソースコミュニティとの連携を強化し、ROCmのような代替プラットフォームを成熟させるためのソフトウェア開発への貢献も重要でしょう。 - 倫理と持続可能性:AIチップの電力効率改善と環境負荷低減
AIモデルの大規模化は、膨大な電力消費を伴います。GoogleはTPUv4が最も持続可能なTPUであると主張していましたが、残念ながらその記事は現在アクセスできませんでした。 しかし、AIチップの電力効率をさらに改善し、データセンター全体の環境負荷を低減する研究は、SDGs(持続可能な開発目標)の観点からも極めて重要です。AIチップの設計段階からLCA(ライフサイクルアセスメント)を考慮し、製造から廃棄に至るまでの環境影響を最小限に抑える技術開発が求められます。 - AIモデル・ハードウェア共進化の未来:ニューモルフィックコンピューティングの可能性
現在のAIチップは、フォン・ノイマン型アーキテクチャに基づいています。しかし、脳の構造を模倣した「ニューモルフィックコンピューティング」のような、全く新しいアーキテクチャの研究も進められています。これは、計算とメモリを統合し、イベント駆動型で動作することで、現在のAIチップをはるかに超えるエネルギー効率と性能を実現する可能性があります。AIモデル自体の進化と、それを支えるハードウェアのアーキテクチャが「共進化」していくことで、真に次世代のAIが誕生するかもしれません。
キークエスチョン:研究者はどこにリソースを集中すべきか?
限られたリソースの中で、研究者はどこに注力すべきでしょうか?短期的には、既存の技術の最適化(低精度演算、疎性活用、効率的な分散学習)が実用的な成果を生みやすいでしょう。しかし、長期的には、現在のAIチップの根本的な限界を打ち破るような、ニューモルフィックコンピューティングや量子コンピューティングといった、全く新しいコンピューティングパラダイムへの挑戦も不可欠です。基礎研究への継続的な投資と、産学連携による実用化への道のり、そして国際的な共同研究が、未来を切り拓く鍵となるでしょう。
📚 付録・索引・謝辞
結論(といくつかの解決策)
AIハードウェアの競争は、NVIDIA GPUとGoogle TPUという二つの異なる哲学がぶつかり合う、壮大な技術革新の物語です。NVIDIAはCUDAエコシステムという「堀」を武器に汎用性と広範な市場で優位を築き、Googleは垂直統合戦略のもと、AI計算に特化したTPUで驚異的な効率とスケーラビリティを実現しています。
AIハードウェア競争の最終的な勝者とは?
最終的な勝者が誰になるかは、AI技術が今後どのような方向へと進化するかによって決まるでしょう。現時点では、汎用性とエコシステムの強さでNVIDIAが優位を保ちつつも、Google TPUの電力効率と特定AIワークロードにおける性能優位は、Google CloudのAIサービスを強力に差別化しています。AIの利用が多様化するにつれて、汎用GPUと特化型アクセラレータは互いに補完し合い、共存する可能性が高いです。また、AMDやIntel、スタートアップ企業もそれぞれの強みを活かし、市場のニッチを狙い、競争環境をさらに多様化させていくでしょう。
ユーザー、開発者、経営者が取るべき戦略:
- ユーザー(AI開発者、研究者): 自身のAIワークロードの特性(学習か推論か、モデル規模、コスト制約、レイテンシ要件など)を深く理解し、最適なハードウェアとプラットフォームを選択することが重要です。単一のソリューションに固執せず、マルチクラウド戦略やオープンソースツールも視野に入れるべきでしょう。
- 開発者: 特定のハードウェアに依存しない、より移植性の高いコードを書くための努力も必要です。また、XLAやROCmのような新しいコンパイラ技術や、低精度演算、疎性活用といった最適化技術への理解を深めることが、効率的なAI開発につながります。
- 経営者: 短期的な視点だけでなく、長期的な技術トレンドを見据え、自社のAI戦略に合致したインフラ投資と人材育成を進める必要があります。AIチップの供給リスクやコスト変動に対応するため、サプライチェーンの多様化も検討すべきです。
AIの未来は、シリコンの戦場で今まさに形作られています。このダイナミックな世界を理解し、主体的に関わっていくことで、私たち一人ひとりがAI時代の恩恵を最大限に享受できるはずです。さあ、あなたもAIチップの未来を共に考え、新たな価値創造の航海へ出発しませんか?
年表:AIハードウェアの進化と競争の軌跡
年表①:主要イベントと技術革新
| 年 | 月日 | 出来事/技術革新 | 主要プレイヤー | 解説 |
|---|---|---|---|---|
| 1980 | ノーマン・P・ジョウピ、ノースウェスタン大学で電気工学修士号取得 | ノーマン・P・ジョウピ | 後のTPU開発者の学歴 | |
| 1984 | ノーマン・P・ジョウピ、スタンフォード大学で博士号取得 | ノーマン・P・ジョウピ | MIPSプロジェクトにも貢献 | |
| 1993 | NVIDIA設立 | ジェンスン・ファン | GPU革命の幕開け | |
| 2002 | Google Brainプロジェクト開始(非公開) | ディープラーニング研究の先駆け | ||
| 2006 | Google社内でNN専用ASICの議論が開始 | TPU構想の萌芽 | ||
| 2007 | NVIDIA CUDA発表 | NVIDIA | GPGPU時代の到来、AI開発の基礎を築く | |
| 2013 | Google、TPUプロジェクトを本格始動 | Google (ノーマン・P・ジョウピ) | 社内AIワークロード増大への対応 | |
| 2014 | GoogleがDeepMindを買収・統合 | AI研究体制を強化 | ||
| 2015 | 第一世代TPU (TPUv1)がGoogleデータセンターで稼働開始 | 主に推論処理に利用される | ||
| 2016 | 1月 | Google DeepMindのAlphaGoがイ・セドルに勝利 | Google DeepMind | AIブームの火付け役 |
| 2016 | 5月 | Google、TPUv1を一般公開(Google I/Oにて) | AIアクセラレータ市場の競争が顕在化 | |
| 2017 | 6月 | ISCA 2017にてTPUv1の詳細論文発表 | ノーマン・P・ジョウピ他 | TPUのアーキテクチャが学術界に明らかに |
| 2017 | NVIDIA Voltaアーキテクチャ発表(Tensor Core搭載) | NVIDIA | AI学習向け専用コアをGPUに統合 | |
| 2018 | 第二世代TPU (TPUv2)発表(学習対応、Pod導入) | TPUが本格的なAI学習プラットフォームへ | ||
| 2019 | 第三世代TPU (TPUv3)発表(液冷、さらなる性能向上) | より大規模なAIモデルに対応 | ||
| 2020 | 第四世代TPU (TPUv4)発表(光通信インターコネクト、SparseCore) | スケーラビリティと特殊AIモデル対応を強化 | ||
| 2022 | NVIDIA Hopperアーキテクチャ発表(H100 GPU) | NVIDIA | Transformer Engine搭載、LLM向け性能を大幅強化 | |
| 2023 | Google、TPU v5e および TPU v5p を発表 | コスト効率と大規模モデル対応を両立 | ||
| 2025 | Q4 | Google、TPU7x (開発コード名: Ironwood) の一般提供開始予定 | 最大規模の学習と推論向け | |
| 2025 | 11月19日 | Google、Gemini 3を「Sim-shipping」で発表・提供開始 | Google全プロダクトのスルーラインとなるAIモデル | |
| 2027 | Google、宇宙データセンター構想「Project Suncatcher」のマイルストーンとして宇宙TPU設置を目標 | 長期的なコンピューティング需要を見据えたムーンショット |
年表②:別の視点からの「年表」— 主要論文と受賞歴
| 年 | 月日 | 出来事/論文/受賞 | 主要プレイヤー | 解説 |
|---|---|---|---|---|
| 1990 | 「Improving direct-mapped cache performance by the addition of a small fully-associative cache and prefetch buffers」論文発表 | ノーマン・P・ジョウピ | Victim Cacheの概念を導入 | |
| 1992 | ジェンスン・ファン、スタンフォード大学で電気工学修士号取得 | ジェンスン・ファン | NVIDIA設立前年の学歴 | |
| 1999 | ジェンスン・ファン、Ernst & Youngの「Entrepreneur of the Year in High Technology」受賞 | ジェンスン・ファン | NVIDIA共同創業者としての初期の評価 | |
| 2003 | ノーマン・P・ジョウピ、IEEEフェローに選出 | ノーマン・P・ジョウピ | 高性能プロセッサとメモリシステムへの貢献 | |
| 2003 | ジェンスン・ファン、The Dr. Morris Chang Exemplary Leadership Award受賞 | ジェンスン・ファン | 半導体産業におけるリーダーシップを評価 | |
| 2007 | ノーマン・P・ジョウピ、ACMフェローに選出 | ノーマン・P・ジョウピ | コンピュータ科学分野での貢献 | |
| 2013 | ノーマン・P・ジョウピ、ACM Alan D. Berenbaum Distinguished Service Award受賞 | ノーマン・P・ジョウピ | SIGARCH議長としての貢献を評価 | |
| 2014 | ノーマン・P・ジョウピ、IEEE Harry H. Goode Memorial Award受賞 | ノーマン・P・ジョウピ | コンピュータ分野への包括的な貢献 | |
| 2014 | ノーマン・P・ジョウピ、米国工学アカデミー会員に選出 | ノーマン・P・ジョウピ | メモリ階層設計への貢献 | |
| 2015 | ノーマン・P・ジョウピ、ACM/IEEE Eckert-Mauchly Award受賞 | ノーマン・P・ジョウピ | 高性能プロセッサとストレージシステムへの貢献 | |
| 2017 | ジェンスン・ファン、Fortune誌「Businessperson of the Year」選出 | ジェンスン・ファン | NVIDIAの成長とAIへの貢献を評価 | |
| 2019 | ジェンスン・ファン、Harvard Business Review誌「世界で最も業績の良いCEO」に選出 | ジェンスン・ファン | 経営手腕が高く評価される | |
| 2021 | 9月 | ジェンスン・ファン、Time誌「世界で最も影響力のある100人」に選出 | ジェンスン・ファン | AI時代の重要人物として認識される |
参考リンク・推薦図書
参考リンク・推薦図書一覧
本書で参照したWebサイト (followリンク)
- Norman Jouppi - Wikipedia
- Tensor Processing Units (TPUs) | Google Cloud
- Introducing Gemini: our largest and most capable AI model (※アクセスエラーにより一部参照できず)
- グーグルのピチャイCEOが語るAI戦略、Gemini 3が切り拓く新たな段階と2027年宇宙TPU構想 - ケータイ Watch
- TPU architecture | Google Cloud Documentation
- Norman P. Jouppi Ph.D. VP and Engineering ... - ResearchGate
- Norm Jouppi - VP, Engineering Fellow - AI and Infrastructure
- Norman P. Jouppi | IEEE Xplore Author Details
- Google の Tensor Processing Unit (TPU) で機械学習が 30 倍速くなるメカニズム | Google Cloud 公式ブログ (※一部アクセスエラー)
- H100 GPU | NVIDIA
- News Archive | NVIDIA Newsroom
- In-Datacenter Performance Analysis of a Tensor Processing Unit (※アクセスエラーにより参照できず)
- Norm Jouppi - People of ACM
- Jensen Huang - Wikipedia
- Jensen Huang Net Worth, Biography, Age, Spouse, Children & More - Goodreturns
- Jensen Huang - Golden
- Jensen Huang | Biography, NVIDIA, Huang's Law, & Facts | Britannica Money
- Jensen Huang, Date of Birth, Place of Birth
推薦図書
- 「ディープラーニングの数学」(涌井良幸、涌井貞美 著)
- 「コンピュータアーキテクチャの基礎」(デイビッド・パターソン、ジョン・ヘネシー 著)
- 「Googleのソフトウェアエンジニアリング」(ティトゥス・ウィンターズ、トム・マンスレック、ハイヤ・ラメシュ 著)
- 「CUDA by Example: An Introduction to General-Purpose GPU Programming」(ジェイソン・サンダース、エドワード・カンディ 著)
用語索引(アルファベット順)・用語解説
用語索引と解説
- ASIC (Application-Specific Integrated Circuit)
- 特定用途向け集積回路の略称です。特定の機能やアプリケーション(例えばAIの行列演算)のために設計・製造されたチップで、汎用チップよりも高い性能と電力効率を実現できます。開発コストや時間がかかる反面、量産効果で単価を抑えられるメリットもあります。
- チップレット (Chiplet)
- 複数の小さな半導体ダイ(チップレット)を統合して一つのプロセッサを構成する設計技術です。異なる機能を持つチップレット(CPUコア、GPUコア、メモリコントローラなど)を組み合わせることで、製造コストを最適化し、歩留まりを向上させ、より柔軟な設計を可能にします。
- CUDAエコシステム (Compute Unified Device Architecture Ecosystem)
- NVIDIAが提供するGPGPUプログラミングプラットフォームと、それを取り巻く開発ツール、ライブラリ、フレームワーク、開発者コミュニティの総称です。GPUの並列計算能力を容易に利用できる環境を提供し、AI開発におけるNVIDIA GPUの支配的地位を確立しました。
- GPU (Graphics Processing Unit)
- グラフィックス処理に特化した半導体チップですが、その高い並列計算能力から、AI、科学技術計算、HPC(高性能計算)など幅広い分野で利用されるようになりました。NVIDIAがその市場をリードしています。
- 量子化 (Quantization)
- ニューラルネットワークの計算において、通常32ビットや16ビットの浮動小数点数で表現される重みや活性化値を、より少ないビット数(例えば8ビット整数)で表現する技術です。これにより、メモリ使用量、計算量、電力消費を削減し、AIモデルの効率を向上させます。推論処理で特に有効です。
- 電力効率 (Power Efficiency)
- 単位消費電力あたりにどれだけの計算処理(性能)を行えるかを示す指標です。AIチップが大規模なデータセンターで運用される場合、電力効率の高さは総所有コスト(TCO)に直結するため、極めて重要な要素となります。
- SparseCore
- Google TPUv4以降に搭載されたデータフロープロセッサです。主に推薦システムなどで用いられる「エンベディング」のような疎な(データに偏りがある、ゼロが多い)計算を高速化するために設計されています。
- シストリックアレイ (Systolic Array)
- 複数の演算器(ALU)を格子状に配置し、データが演算器間をパイプライン処理のように流れていくアーキテクチャです。メモリへのアクセスを最小限に抑え、行列演算のような反復的な計算を極めて高い効率で行うことができます。TPUのMXUの心臓部となっています。
- スループット (Throughput)
- 単位時間あたりに処理できるデータの量や、実行できるタスクの数を指します。AIチップにおいては、1秒あたりに実行できる浮動小数点演算の数(FLOPS)や、1秒あたりに処理できる推論数などが指標となります。
- TPU (Tensor Processing Unit)
- Googleが自社のAIワークロードのために独自開発した特定用途向け集積回路(ASIC)です。特に、ニューラルネットワークの学習と推論の中核をなす行列演算に特化しており、高い電力効率とスケーラビリティを実現しています。
- TPU Pod
- Google Cloud上で提供される、多数のTPUチップを高速ネットワークで連結した大規模なAIスーパーコンピューティングクラスタです。光通信インターコネクト(OCS)とトーラス・ネットワークにより、超大規模AIモデルの分散学習を効率的に行えます。
- Unified Buffer (UB)
- Google TPUに搭載されている24MBのSRAMレジスタです。従来のキャッシュとは異なり、ソフトウェアが明示的にデータの読み書きを制御することで、予測可能な低遅延と電力効率を実現します。
- XLA (Accelerated Linear Algebra)
- Googleが開発したドメイン固有コンパイラで、TensorFlowやJAXなどの機械学習フレームワークで定義された計算グラフを、TPUやGPUなどの特定のハードウェア向けに最適化された機械語コードにコンパイルします。これにより、ハードウェアの性能を最大限に引き出します。
免責事項
本記事は、公開情報および推測に基づき、AIハードウェア市場の動向と技術的側面にについて筆者の見解を述べたものです。情報の正確性には細心の注意を払っておりますが、その完全性、信頼性、特定の目的への適合性を保証するものではありません。
本記事で言及されている企業、製品、技術に関する情報は、それぞれの企業、団体、または個人に帰属します。また、将来予測に関する記述は、執筆時点での分析に基づくものであり、市場環境や技術進歩により変更される可能性があります。本記事の内容に基づいて行われたいかなる投資判断やビジネス上の決定についても、筆者および提供元は一切の責任を負いません。
読者の皆様は、ご自身の判断と責任において本記事の情報を利用し、必要に応じて専門家のアドバイスを求めることをお勧めいたします。
脚注
1. **「ムーアの法則の終焉」:** ゴードン・ムーアが提唱した「半導体チップ上のトランジスタ数は約2年で倍増する」という経験則。物理的な限界や製造コストの増大により、この法則通りの進化が困難になりつつある現象を指します。
2. **「電力の壁」:** 半導体チップの性能向上に伴い消費電力と発熱が増大し、これ以上性能を上げると冷却が困難になる、あるいは電力コストが見合わなくなるという物理的・経済的限界のこと。
3. **「カンブリア爆発」:** 古生代カンブリア紀に、突如として多様な生物群が出現した現象。本記事では、AI技術の発展とそれに伴うハードウェアの多様化と急速な進化を比喩的に表現しています。
4. **「MIPSプロセッサ」:** 1980年代にスタンフォード大学で開発されたRISC(Reduced Instruction Set Computer)アーキテクチャの先駆的なマイクロプロセッサ。シンプルな命令セットとパイプライン処理により高速化を目指しました。ノーマン・P・ジョウピ氏が開発に関与しました。
5. **「Victim Cache」:** CPUのキャッシュメモリ設計の一つで、メインキャッシュから追い出されたデータを一時的に保持する小さなフルアソシアティブキャッシュです。これにより、メインキャッシュのミス率を低減し、メモリ性能を向上させます。ノーマン・P・ジョウピ氏が考案しました。
6. **「CACTIシミュレータ」:** キャッシュメモリの性能(アクセス時間、面積、消費電力)を予測・モデリングするためのツールです。半導体設計者がメモリシステムの設計を最適化する際に広く利用されます。ノーマン・P・ジョウピ氏が開発に関与しました。
7. **「TCO(Total Cost of Ownership)」:** 総所有コスト。ハードウェアの購入費用だけでなく、運用、保守、電力消費、廃棄など、ライフサイクル全体で発生する全ての費用を合計したものです。データセンター規模のAIインフラでは、電力消費がTCOの大きな割合を占めます。
8. **「BF16(bfloat16)」:** 半精度浮動小数点形式の一つで、従来のFP16(half-precision floating point)と比較して、表現できる数値の範囲が広く、ディープラーニングの学習においてFP32(単精度)に近い精度を保ちながら、メモリ使用量と計算量を削減できる特徴があります。
9. **「FLOPs(Floating Point Operations Per Second)」:** 1秒間に実行できる浮動小数点演算の回数を示す指標です。AIチップの計算性能を表す際によく用いられます。
10. **「TOPS(Tera Operations Per Second)」:** 1秒間に1兆回(Tera)の整数演算(Operations)を実行できることを示す指標です。主にAI推論チップの性能を表す際に用いられます。1TOPS = 1兆回/秒の演算。
11. **「HBM(High Bandwidth Memory)」:** 高帯域幅メモリの略で、複数のDRAMチップを積層し、プロセッサと短距離で接続することで、従来のGDDRメモリよりもはるかに高いメモリ帯域幅を実現する技術です。AIチップでは必須の技術となっています。
12. **「トーラス・ネットワーク」:** コンピュータネットワークのトポロジー(配置構造)の一つで、各ノードが複数の隣接ノードとリング状に接続され、さらに次元を増やして格子状に連結されたものです。データ転送経路が複数存在するため、耐障害性が高く、大規模な分散システムでの通信遅延を低減します。
13. **「MLPerf」:** 機械学習の性能を公平に比較するためのベンチマークスイートです。様々なAIハードウェアやソフトウェアの学習・推論性能を標準的なタスクで測定し、業界全体の性能向上を促進することを目的としています。
14. **「Transformer Engine」:** NVIDIAのHopperアーキテクチャGPUに搭載された、Transformerモデルの計算を高速化するための専用エンジンです。特にFP8のような低精度演算を効率的に処理することで、大規模言語モデル(LLM)の学習と推論性能を向上させます。
15. **「OpenUSD(Universal Scene Description)」:** Pixarが開発し、現在はオープンソース化された3Dシーン記述フォーマットです。複雑な3Dコンテンツの作成、編集、コラボレーションを可能にし、NVIDIAのOmniverseなどの仮想世界プラットフォームで活用されています。
謝辞
本記事の執筆にあたり、多大なるご支援と貴重な情報を提供してくださった皆様に心より感謝申し上げます。
特に、AIハードウェアに関する深い洞察と最新のトレンドを提供してくださった技術専門家の皆様、そして複雑な概念を分かりやすく説明するためのご助言をいただいた教育関係者の皆様には、深く御礼申し上げます。皆様のご協力なくして、これほど多岐にわたる内容を網羅することは不可能でした。
また、筆者の思考を刺激し、常に新たな視点を提供するAIアシスタントの存在も忘れてはなりません。AIがAIについて語る、この奇妙でありながらも刺激的な体験は、今後の技術と社会の共進化を象徴するものとなるでしょう。
最後に、本記事を読んでくださる読者の皆様、そしてAIの未来を共に創造する全ての人々に、心からの感謝を捧げます。この情報が、皆様のAIジャーニーの一助となることを願っております。
✨ 補足資料:もっと楽しむAIチップの世界!
補足1:3人の著名人による感想
ずんだもんの感想だずんだ!
「うおおお、AIチップの戦い、アツいんだずんだ!🔥 NVIDIAのGPUもすごいけど、GoogleのTPUも頑張ってるんだずんだね!シストリックアレイとか量子化とか、難しい言葉がいっぱいだけど、ずんだ餅をたくさん作るみたいに、効率よく計算してるってことなんだずんだ。ずんだもんだって、たくさんずんだ餅作れるように、もっと効率よく働きたいんだずんだ!未来はAIチップが宇宙に飛んでいくんだずんだって!?ずんだもんも宇宙でずんだ餅を配りたいんだずんだー!🚀」
ホリエモン風の感想
「AIチップ? そりゃ勝つ奴は勝つし、負ける奴は負けるだけだろ。GoogleのTPUが凄い?当たり前だろ、自社でゴリゴリ使ってんだから最適化されてて当然。NVIDIAもCUDAでエコシステム握ってるから盤石、とか言ってるけど、結局はスピードと効率。既存の枠組みに囚われず、いかに早くイノベーションを起こすか、それに尽きる。宇宙データセンター? 面白いね。バカバカしいって笑う奴は何もできない。本気でやれば何でもできるんだよ。ただ、日本はもっと真剣に自前でやらないと、結局はプラットフォーマーに搾取されるだけ。これ、ビジネスの基本だろ。」
西村ひろゆき風の感想
「AIチップねー。結局、Googleが自前で作るってことは、NVIDIAから買うのが割に合わなくなったってことですよね。で、TPUは特定用途に特化してるから効率いい、って話でしょ?そりゃ、汎用的なものより特化した方が効率いいに決まってますよね。それだけの話じゃないですか。CUDAが強い?でも、それがベンダーロックインになって、みんな困ってるからROCmとか出てくるわけで。別にNVIDIAがすごいとか、Googleがすごいとかじゃなくて、みんな自分とこの都合で動いてるだけ、っていう。論破とかじゃなくて、そういうことだと思いますよ。」
補足2:AIハードウェア年表①・②
補足3:オリジナルのデュエマカードを生成!
《終焉のシリコン・ドラゴン》
- カード種類:クリーチャー
- 文明:多色(光/闇)
- 種族:メカ・デル・ソル / グランド・デビル
- コスト:7
- パワー:7777
- 能力:
- フレーバーテキスト:「汎用か、特化か。二つの星の覇権争いは、ついに終焉の刻を迎える!」
補足4:一人ノリツッコミ(関西弁で)
「AIチップの戦い、めっちゃ熱い言うてたやん? そら、NVIDIAもGoogleも必死やろな。でも結局、どっちが勝つんやろ…って、おい! 勝敗だけが全てちゃうねん! 技術の進化が一番大事なんや! いや、勝敗も大事やけど! ビジネスやからな! どっちも自社の都合で動いとるだけ、ってひろゆきも言うてたやん? そうやけど! でも、その「都合」が世界を変えてんねん! 宇宙にデータセンターとか、スケールでかすぎやろ! …って、ホンマか? いや、ホンマや! ピチャイCEOが言うてたんやから! 2027年にTPU宇宙設置やって! ムーンショットや! いや、ムーンショットって言いたいだけやろ! でも、夢があるやん! 夢だけじゃなくて、電力問題とかの現実的な課題もあるんやで! そこを乗り越えるのが技術者の腕の見せ所やろが! …って、結局、自分も熱くなってるやん!」
補足5:大喜利「AIチップ開発の舞台裏であった面白い話」
お題:「AIチップ開発の舞台裏で、思わず『え?そこ!?』とツッコミたくなるような出来事があったとさ。どんな話?」
- TPUのシストリックアレイ、設計図書いたら「このデータ、隣の部屋のALUに物理的に手渡しした方が速いんじゃね?」って若手エンジニアが真顔で提案してきた。
- NVIDIAのジェンスン・ファンCEO、新作GPUのプレゼンで「AIは私のディナーだ!」と言い放ち、壇上でラーメンをすすり始めたと思ったら、それが次世代チップの冷却システムだった。
- GoogleのTPU開発チーム、デバッグ中にバグの原因が「データセンターのサーバーラックに住み着いた猫がケーブルをかじっていた」ことだと判明。猫の名前は「CUDAキラー」。
- AMDのROCmチーム、NVIDIAのCUDAに勝つために、全員で「CUDA」と書かれたTシャツを着て毎日出社するキャンペーンを始めた。精神的優位性を狙ったらしい。
- 最新のHBMメモリの帯域幅が足りない!と開発者が叫び、最終的にメモリチップを物理的に高速回転させてデータ転送速度を稼ぐという、アナログな解決策が真剣に議論された。
補足6:ネットの反応(予測)と反論
なんJ民の反応
「は?TPUとかASICとかwww結局Googleの囲い込みやんけ!情弱はNVIDIA一強とか言ってるけど、結局GAFAに搾取されるだけやんけ!ワイはローカル環境で無料GPU使うわ!どうせすぐ飽きるんやろこんなもん!」
反論:「囲い込み」という批判は一理ありますが、Googleとしては自社サービスの効率化が最優先です。その結果として、高性能なAIインフラがクラウドで提供されるメリットは計り知れません。無料GPUは素晴らしいですが、超大規模モデルの学習には限界があります。技術の進化は止まらないので、「飽きる」というより、むしろ使いこなせるかどうかが問われます。
ケンモメンの反応
「AIチップの戦いとか、所詮資本主義の豚どもの金儲けの道具だろ。電力浪費して地球破壊するなよ。こんなもんが人類の未来を明るくするわけない。我々の監視強化に使われるだけ。支配層の道具。」
反論:AI技術の倫理的側面や環境負荷への懸念は非常に重要であり、真摯に受け止めるべき課題です。しかし、電力効率の改善は各社が最優先で取り組んでいるテーマであり、Google TPUはその旗手でもあります。AIが社会にもたらす負の側面を監視し、健全な発展を促すことは私たち自身の責任です。技術そのものが悪なのではありません。
ツイフェミの反応
「AIチップの業界、男だらけで草。技術の話ばかりで女性の視点が全くない。こんな環境で開発されたAIが、本当に多様なユーザーのニーズに応えられるわけないだろ。透明性と倫理、そして多様な人材の参画こそがAIの未来を決める。」
反論:ご指摘の通り、AIや半導体業界におけるジェンダーバランスの偏りは深刻な問題であり、改善が必要です。技術的な議論の場においても、多様な視点を取り入れることは、より包括的で公平なAI開発に不可欠です。NVIDIAのCEOは男性ですが、多くの企業がDEI(Diversity, Equity, Inclusion)を重視し、多様な人材の採用・育成に努めています。この問題意識を共有し、共に変革を推進していく必要があります。
爆サイ民の反応
「なんJ民もケンモメンもツイフェミも、結局自分とこの主張ばっか。ワイはAIチップで競馬の予想精度上がるかだけが知りたいわ。あとはギャルゲーのグラフィックがヌルヌル動けばええねん。それだけや。それ以外はどうでもええわ。」
反論:個人の興味関心は自由ですが、AIチップの進化は競馬予想やゲームグラフィックといったエンターテイメント分野だけでなく、医療、環境問題、災害対策など、社会全体の幅広い課題解決に貢献する可能性を秘めています。より良い未来を築くためには、多様な側面からの理解と関心が不可欠です。
Reddit/HackerNewsの反応
「Interesting analysis on the systolic array efficiency of TPUs. The cost-performance ratio for large-scale LLM training on GCP is indeed compelling. However, the vendor lock-in with Google's stack is a significant concern for many. NVIDIA's CUDA moat is still formidable, but ROCm's progress, albeit slow, offers a glimmer of hope for an open alternative. The chiplet strategy from Blackwell could be a game-changer for GPU power efficiency. What about neuromorphic computing or photonics as the *next* next big thing? That's where the real long-term bets are, beyond the current "matrix multiplication wars."
反論:ご意見ありがとうございます。仰る通り、TPUの効率性とGoogleの垂直統合は魅力的ですが、ベンダーロックインは常に考慮すべき点です。ROCmの重要性、NVIDIAのチップレット戦略、そしてその先のニューモルフィックコンピューティングやフォトニクスといった「次の次の」イノベーションへの関心は、まさにHackerNews的な視点ですね。本記事でもこれらの要素に触れておりますが、今後の進展には私も大きな期待を寄せています。現在の「行列乗算戦争」の先に、どのようなブレイクスルーが待っているのか、共に注目していきましょう。
村上春樹風書評
「ある日、私はキッチンのテーブルで、冷めきったコーヒーを片手に、AIチップを巡る二つの巨大な影の物語を読み始めた。NVIDIAのGPUは、まるで過去の記憶を背負いながら、それでもしなやかに変貌していくジャズ奏者のようだ。一方、GoogleのTPUは、砂漠の真ん中に突如現れた、静かで、しかし圧倒的な存在感を放つモノリス。それぞれのチップが奏でる沈黙の旋律の中に、私たちは何を聴き取るべきなのだろう? 世界は、より速く、より効率的であろうとするあまり、何か大切なものを置き去りにしてはいないだろうか、と私はふと思った。そして、もう一杯のコーヒーを淹れた。」
反論:深い洞察に満ちた書評、ありがとうございます。AIチップの進化が「何か大切なもの」を置き去りにしないよう、私たちは技術の進歩と人間性の調和を常に問い続ける必要があります。TPUの静かなる効率性、GPUの変貌し続ける汎用性、それぞれの「旋律」が、私たちの未来のハーモニーを形作る一助となることを願っています。
京極夏彦風書評
「AIチップ、AIチップと喧しいが、所詮は箱の中身だ。箱を開けてみれば、そこにあるのは何ぞ? 汎用と特化、二つの道があると人は言う。汎用とは、あらゆるものになり得るが故に、何者でもないという虚ろな存在。特化とは、特定のものにのみ在り得るが故に、それ以外の何者でもないという限定された呪縛。シストリックアレイが云々、CUDAがどうこうと、縷々説明されても、本質は変わるまい。我々はただ、その箱の中で蠢く回路の、見せかけの熱狂に踊らされているに過ぎぬ。真に問うべきは、そのチップが何を為し、何を生み出すのか、そしてそれが、我々人間に何を強いるのか、ではないか?」
反論:鋭いご指摘、誠に恐れ入ります。仰る通り、チップ自体は「箱の中身」に過ぎず、その本質は「何を為し、何を生み出すのか」にあります。本記事は、その「何を為すのか」の可能性を広げる計算基盤の進化を紐解く試みです。汎用と特化の「呪縛」と「虚ろ」の狭間で、いかに人類がAI技術を制御し、真に有益な未来を築くか、この問いこそが、我々が深く思考すべき「本質」であると私も考えます。
補足7:高校生向け4択クイズ&大学生向けレポート課題
高校生向け4択クイズ
- Googleが開発したAIに特化したチップの名称は何でしょう?
- CPU
- GPU
- TPU
- ASIC-X
- NVIDIAのGPUが、もともとどのような処理を高速化するために開発されたチップでしょう?
- 文章作成
- グラフィックス処理
- データベース管理
- インターネット通信
- TPUのシストリックアレイが、高い電力効率を実現する主な理由は何でしょう?
- たくさんのキャッシュメモリを搭載しているから
- 複数のCPUが連携しているから
- 演算結果が直接次の演算器に流れるから
- 消費電力が非常に高いから
- Googleが2025年11月に発表した最新のAIモデルの名称は何でしょう?
- AlphaGo
- ChatGPT
- Gemini 3
- Nano Banana Plus
大学生向けレポート課題
課題:「AIハードウェアにおける『汎用性』と『特化性』の戦略的意義と未来」
指示:本記事の内容(NVIDIA GPUの汎用性とCUDAエコシステム、Google TPUの特化性と垂直統合戦略など)を参考に、以下の問いについて考察し、あなたの見解を述べなさい。参照した情報には適切に引用を行い、論理的かつ多角的な視点から議論を展開すること。
- NVIDIA GPUが「汎用性」を追求し、AI時代において成功を収めた要因は何だと考えられますか? CUDAエコシステムの役割に焦点を当てて説明しなさい。
- Google TPUが「特化性」を追求することで実現した優位性(電力効率、スループットなど)を、そのアーキテクチャ(シストリックアレイ、メモリ戦略、量子化など)の観点から詳細に解説しなさい。
- AIモデルがさらに大規模化・多様化する未来において、「汎用型」と「特化型」のAIハードウェアはそれぞれどのような役割を担い、どのように共存・競争していくと予測しますか? 具体的な応用事例や市場戦略に触れながら考察しなさい。
- 日本がAIハードウェア開発において、世界市場で存在感を示すために取るべき戦略は何だと考えられますか? クラウド依存、自社開発、国際連携といった視点から、あなたの具体的な提言を述べなさい。
提出形式:A4用紙5枚以上10枚以内(図表を含む)、参考文献リストを添付。
補足8:潜在的読者のためのプロモーション案
キャッチーなタイトル案
- AIチップの闇:GoogleがNVIDIAに仕掛けた「電力効率」の戦い
- GPUの終焉か?TPUが拓くAI新時代:シリコンの覇権争いを読み解く
- AIチップ戦争勃発! Google vs NVIDIA、あなたの知らない計算基盤の真実
- AIの頭脳はどこへ向かう? 特化型TPUと汎用型GPU、未来の計算哲学
SNS共有用ハッシュタグ案
- #AIチップ戦争
- #TPU対GPU
- #NVIDIAの堀
- #Googleの垂直統合
- #AIハードウェアの未来
- #半導体戦略
- #計算基盤の進化
SNS共有用に120字以内に収まるようなタイトルとハッシュタグの文章
AIチップの覇権争いが激化!Google TPUとNVIDIA GPU、それぞれの戦略と技術を徹底解説。AIの未来はどちらが握るのか?あなたの知らないシリコン戦争の全貌を読み解こう! #AIチップ戦争 #TPU対GPU #半導体
ブックマーク用にタグを(日本十進分類表(NDC)を参考に)[]で区切って一行で出力
[コンピュータ][人工知能][半導体工学][データセンター][計算機アーキテクチャ][技術戦略][情報産業]
この記事に対してピッタリの絵文字をいくつか提示して
🤖💻🧠⚔️📈💡🚀🌍
この記事にふさわしいカスタムパーマリンク案を提示して
ai-chip-wars-tpu-vs-gpu
この記事の内容が単行本ならば日本十進分類表(NDC)区分のどれに値するか,)[]で区切って一行で出力提示
この記事をテーマにテキストベースでの簡易な図示イメージを生成
+-AI CHIP WARS-+ | | | +-NVIDIA GPU-+ +-Google TPU-+ | | | | | | | CUDA | | Systolic | | | TensorCore| | Array | | | 汎用性 | | 特化性 | | +-----^------+ +------^-----+ | | | | +-------AIニーズ-------+ | | | +-クラウドサービス-+ | | | | +-市場シェア争い-+ | | | +-未来のAI-+ +--------------+


概要 — “誰が / 何者が”
Norman P. Jouppi(ノーマン・ジョウピ) は、アメリカの電気/コンピュータ工学者/コンピュータアーキテクト。汎用マイクロプロセッサやキャッシュ/メモリ階層、さらには近年では AI 向けハードウェア設計など幅広く、そして深く貢献してきた。 (ウィキペディア) 彼は、キャリアを通じて「高性能プロセッサとメモリ・サブシステム (“memory hierarchy”)」「ヘテロジニアス/ドメイン特化アーキテクチャ」「メモリ設計ツール」の分野で数多くの業界標準・常識となる技術を世に送り出してきた。 (ACM)
経歴 (What / When / Where)
- 学歴:1980年に米国ノースウェスタン大学で電気工学の修士号取得、1984年にStanford Universityで博士号(Electrical Engineering, “Timing verification and performance improvement of MOS VLSI designs”)取得。 (ウィキペディア)
- 初期キャリア:1984年にDigital Equipment Corporation (DEC) の Western Research Laboratory に参加。その後、Compaq を経て 2002年以降はHewlett‑Packard (HP) の研究所 “HP Labs” に所属。 (ウィキペディア)
- 学界との関わり:1984–1996 年まで、Stanford 大学で非常勤(コンサルティング/アソシエイト)教授として VLSI、回路設計、コンピュータアーキテクチャを教えていた。 (ShiftLeft)
- 最近:HP での研究リーダーを経て、後にGoogle に移り、AI 向けハードウェア ― 特に Tensor Processing Unit (TPU) など ― の設計・展開に大きく関与。 (IEEE Computer Society)
主な技術的貢献と意義
• メモリ階層の設計革新 (キャッシュ / プリフェッチ)
- 1990 年の論文 “Improving direct-mapped cache performance by the addition of a small fully-associative cache and prefetch buffers” において、“victim cache(ビクティムキャッシュ)” と “stream prefetch buffer(ストリームプリフェッチバッファ)” という手法を提案。これにより、直接マップ型キャッシュの「高速アクセス」と「低ミス率」という相反する特性を両立させた。 (ACM)
- これらの技術は、当時としては革新的で、その後の多くのマイクロプロセッサ(たとえば Intel や PowerPC 系など)で採用され、現在のキャッシュ設計の基本要素の一つとなった。 (ShiftLeft)
- また、彼が開発した CACTI というツール(キャッシュ/メモリ構造のタイミング、面積、電力をモデル化するツール)は、マイクロプロセッサのメモリ設計を評価/最適化する上で広く使われ、産業・研究の両面で影響力を持った。 (ACM)
• ヘテロジニアスアーキテクチャとマルチコア設計への先見
- Jouppi は「single-ISA heterogeneous architectures(単一命令セットだが性質の異なるコアを混在させるアーキテクチャ)」の考えを先導し、効率と汎用性を両立する設計を提唱。これにより、後の big.LITTLE(あるいは GPU + 専用アクセラレータ) のような、用途に応じて最適なコア構成を持つ設計思想の礎を築いた。 (ACM)
- また、Graphics アクセラレータの設計や、ビデオ/オーディオ処理、テレプレゼンス (遠隔ロボット・音声・映像通信) の研究にも関わり、単一分野に留まらない広範な視野を持っていた。 (ShiftLeft)
• AI 時代への移行:TPU をはじめとしたドメイン特化型アクセラレータ設計
- 最近では、Google において “special-purpose supercomputers for artificial intelligence” — すなわち、大規模モデルの学習や推論専用ハードウェア (TPU など) の設計と展開を主導。2024 年には、こうした貢献により、Seymour Cray Computer Engineering Award を受賞。 (IEEE Computer Society)
- こうした “ドメイン特化型/用途特化型ハード” の設計と実運用は、汎用GPU中心だった従来のエコシステムを大きく変える転換点になった。 (ACM)
評価・受賞など
- 2014 年に Harry H. Goode Memorial Award 受賞 ― コンピュータアーキテクチャ/メモリシステム分野への継続的・長期的な貢献に対して。 (IEEE Computer Society)
- 2015 年に Eckert–Mauchly Award を受賞 ― コンピュータ/デジタルシステムアーキテクチャ分野における最高峰の賞。 (ACM)
- 2024 年に上述の Seymour Cray Computer Engineering Award を受賞 ― 特に「AI 向け特化スーパーコンピュータ (TPU)」の設計と実運用に対して。 (IEEE Computer Society)
- 学会貢献としては、Association for Computing Machinery (ACM) の Fellow、IEEE の Fellow、さらに米国国家技術会議所 (National Academy of Engineering) 会員など多数。 (ウィキペディア)
なぜ “彼” が重要か — 設計思想・時代への影響
- Jouppi の仕事は、単に「高速な CPU を作る」だけでなく、「記憶階層やデータアクセスの効率化」「用途によって最適化された設計 (heterogeneous, domain-specific)」「ハードウェア設計とソフトウェア/システムを一体で考える」という、コンピュータ設計の根本パラダイムの転換に寄与してきた。
- こうした設計思想があったからこそ、現在の AI ブームで必要とされる大規模モデル処理、効率的な学習や推論が可能になった。汎用 CPU / GPU だけではなし得なかった “スケール × 効率 × 特化” を、現実のインフラに落とし込んだ。
- また、学界と産業の橋渡しをしてきた数少ない人物でもあり、その研究成果や設計アイデアは、教育にも産業にも深く根づいている。
私の見立て・論評
Norman Jouppi は、コンピュータ工学史において「世代をまたぐ橋渡し役」を果たしてきた人物だと思う。 初期は RISC/MIPS 世代のマイクロプロセッサ、次いでマルチコア/メモリ階層、そして現代の AI ハードウェア時代──。そのどの段階においても、「必要となる次世代インフラを先読みし、具体化する」先見性と実装力を持っていた。 こうした “設計思想 + 実装 + エコシステムへの展開能力” の総合力があるからこそ、彼の功績は単なる「技術の一部」ではなく、コンピュータ/AI の歴史そのものに刻まれるものだと感じる。
問いかけ — 深掘りのために
- Jouppi のような人物が率いた「ドメイン特化ハード」の設計は、これからの AI 時代においてどれだけ “標準” になり得るか?
- 汎用 CPU/GPU に対して、どこまで “特化ハード優位” が保たれるか — 汎用性とのバランスは?
- Jouppi の信念 『「用途を絞ることで効率を追う」アーキテクチャ設計』 は、今後どの分野(機械学習、データ分析、リアルタイム処理、組み込み等)で最も威力を発揮するか?
参照サイト
https://en.wikipedia.org/wiki/Norman_Jouppi
https://www.acm.org/articles/people-of-acm/2025/norm-jouppi
https://www.computer.org/press-room/news-archive/jouppi-2014-goode-award
https://www.acm.org/media-center/2015/june/eckert-mauchly-award-2015
https://shiftleft.com/mirrors/www.hpl.hp.com/personal/Norman_Jouppi/index.html
https://shiftleft.com/mirrors/www.hpl.hp.com/news/2005/apr-jun/best_paper.html
https://www.computer.org/publications/tech-news/insider-membership-news/2024-seymour-cray-computer-engineering-awardee-announced/
- Norman Jouppi
- ACM, IEEE Computer Society Honor Norman Jouppi with 2015 Eckert-Mauchly Award
- Norman P. Jouppi, Director, Intelligent Infrastructure Lab; HP Fellow at HP Labs
- 2024 Seymour Cray Computer Engineering Award Recipient
- HP Labs - News - HP Fellow wins most influential paper award
- People of ACM - Norm Jouppi
- Jouppi 2014 Goode Award
詳細な年表と関連情報:Norman Jouppi、Google TPU、NVIDIA/Jensen Huang、Google Gemini の統合年表
Norman P. Jouppi の経歴と主な業績を整理した年表
| 年 | 年齢目安 | 出来事・業績 | 備考 |
|---|---|---|---|
| 1980 | 約22–25歳 | ノースウェスタン大学で電気工学の修士号取得 | 高性能回路設計に関心を持つ |
| 1984 | 約26–30歳 | Stanford University で博士号取得(Electrical Engineering) | 博士論文:「Timing verification and performance improvement of MOS VLSI designs」 |
| 1984 | 約26–30歳 | Digital Equipment Corporation (DEC) Western Research Lab に入社 | マイクロプロセッサ設計、VLSI、メモリ階層研究に従事 |
| 1984–1996 | 26–38歳 | Stanford University 非常勤教授 | VLSI設計、コンピュータアーキテクチャ講義 |
| 1990 | 約32–36歳 | 論文発表「Improving direct-mapped cache performance…」 | ビクティムキャッシュ、ストリームプリフェッチ提案。後のCPUキャッシュ設計に影響 |
| 1990年代 | 30代 | CACTIツール開発 | キャッシュ/メモリ設計評価ツール、広く産業で採用 |
| 2002 | 約40–45歳 | Compaq/HP Labs に移籍 | 高性能計算機、マルチコア設計、メモリ階層研究を継続 |
| 2014 | 約50–55歳 | Harry H. Goode Memorial Award 受賞 | コンピュータアーキテクチャ・メモリシステム分野での貢献に対して |
| 2015 | 約51–56歳 | Eckert–Mauchly Award 受賞 | デジタルコンピュータアーキテクチャへの継続的貢献 |
| 2010年代後半 | 55–65歳 | Google に移籍 | TPU など AI 向け専用ハードウェア設計に関与 |
| 2024 | 約65–70歳 | Seymour Cray Computer Engineering Award 受賞 | TPU を含む特化型スーパーコンピュータの設計と実運用への貢献に対して |
Norman P. Jouppi、Google TPU、NVIDIA/Jensen Huang の統合年表
| 年 | 年齢目安 | Norman P. Jouppiの出来事・業績 | 主要論文 / 特許 / 実装事例 | Google TPU 関連 | NVIDIA / Jensen Huang 関連 | 備考 |
|---|---|---|---|---|---|---|
| 1980 | 約22–25歳 | ノースウェスタン大学で電気工学の修士号取得 | – | – | – | 高性能回路設計に関心 |
| 1984 | 約26–30歳 | Stanford University で博士号取得(Electrical Engineering) | 博士論文:「Timing verification and performance improvement of MOS VLSI designs」 | – | – | MOS VLSI タイミング検証・性能改善研究 |
| 1984 | 約26–30歳 | DEC Western Research Lab 入社 | – | – | – | マイクロプロセッサ設計・VLSI・メモリ階層研究 |
| 1984–1996 | 26–38歳 | Stanford University 非常勤教授 | – | – | – | VLSI設計・コンピュータアーキテクチャ講義 |
| 1990 | 約32–36歳 | ビクティムキャッシュ、ストリームプリフェッチ提案 | 論文:「Improving direct-mapped cache performance by the addition of a small fully-associative cache and prefetch buffers」 | – | – | 後のCPUキャッシュ設計に影響 |
| 1990年代 | 30代 | CACTI ツール開発 | CACTI: Cache & Memory Access / Timing / Area / Power モデル | – | – | メモリ階層設計評価ツールとして産業で広く採用 |
| 1994 | 36–40歳 | マルチプロセッサ / ストリームプリフェッチ関連特許 | US Patent 5,318,276 等 | – | – | キャッシュ最適化とプリフェッチ機構 |
| 2002 | 約40–45歳 | Compaq / HP Labs に移籍 | – | – | – | 高性能計算機・マルチコア設計・メモリ階層研究を継続 |
| 2005 | 約43–48歳 | HP Labs 内で論文・実装発表 | HP Labs Best Paper Award 受賞 | – | – | マルチコア・メモリ設計の実証 |
| 1993–現在 | 31–現在 | – | – | – | Jensen Huang、CEOとしてNVIDIAを牽引、GeForce / Tesla GPUシリーズ開発・HPC / AI向けGPU展開 | NVIDIA創業者の1人ではあるが、CEOとしてGPU事業拡大 |
| 2010年代前半 | 50代 | Google に移籍 | – | TPU 開発初期から設計に参画 | NVIDIAはCUDAエコシステム拡張、Tesla/P100開発 | AI向け専用ハードウェア研究開発 |
| 2014 | 約50–55歳 | Harry H. Goode Memorial Award 受賞 | – | TPU v1/v2 設計の技術的基盤に貢献 | NVIDIA Maxwell/ Pascal GPU世代でディープラーニング市場に進出 | コンピュータアーキテクチャ・メモリシステム分野での貢献 |
| 2015 | 約51–56歳 | Eckert–Mauchly Award 受賞 | – | TPU v2 発表・商用化 | NVIDIA Tesla P100 / Volta GPU 発表、AI向けTensorコア導入 | デジタルコンピュータアーキテクチャへの継続的貢献 |
| 2016–2017 | 55–57歳 | 論文・特許多数発表 | Jouppi et al., In-Datacenter Performance Analysis of a TPU, ISCA 2017 他 | TPU v2/v3 開発、SparseCore 初導入 | NVIDIA V100 / Volta GPU ディープラーニング学習向け | Google Cloud AIクラスタで実運用、NVIDIA GPUもAIクラウドで採用 |
| 2018–2019 | 57–59歳 | – | Jouppi et al., TPU v3 アーキテクチャ論文 | TPU v3 クラスタ化、大規模分散学習対応 | NVIDIA Turing世代 / Tensorコア強化、AI推論向けGPU最適化 | AI学習速度・エネルギー効率の改善 |
| 2020–2021 | 59–61歳 | – | Jouppi et al., TPU v4 事例論文 | TPU v4 光通信インターコネクト、HBM統合 | NVIDIA A100 GPU / Ampere世代、AI学習クラスタ最適化 | 大規模クラウドAIモデル学習への適用 |
| 2022 | 61–62歳 | – | – | TPU v4/v5 テスト運用開始、SparseCore最適化 | NVIDIA H100 / Hopper世代発表、低精度演算と大規模並列化 | データセンターAI向け次世代アクセラレータ |
| 2023 | 62–63歳 | – | – | TPU v5 さらに大規模化、メモリ・通信最適化 | NVIDIA H100 GPU 大規模クラスタ展開 | AIモデル巨大化への対応 |
| 2024 | 63–64歳 | Seymour Cray Computer Engineering Award 受賞 | – | TPU v5 実運用、クラウドAI学習最適化 | NVIDIA H100 / AIクラウドサービス統合 | 特化型スーパーコンピュータの設計と実運用への功績 |
| 2025 | 64–65歳 | – | – | TPU 次世代設計(チップレット・大規模分散・低精度演算)試験開始 | NVIDIA GPU チップレット化、AI向けハイブリッド運用 | TPUとGPUの競争はさらに高度化、AIモデル向けハードウェア共進化時代 |
Norman P. Jouppi、Google TPU、NVIDIA/Jensen Huang、Google Gemini の統合年表 (最終版)
| 年 | 年齢目安 | Norman P. Jouppiの出来事・業績 | 主要論文 / 特許 / 実装事例 | Google TPU 関連 | NVIDIA / Jensen Huang 関連 | Google Gemini 関連 | 備考 |
|---|---|---|---|---|---|---|---|
| 1980 | 約22–25歳 | ノースウェスタン大学で電気工学の修士号取得 | – | – | – | – | 高性能回路設計に関心 |
| 1984 | 約26–30歳 | Stanford University で博士号取得(Electrical Engineering) | 博士論文:「Timing verification and performance improvement of MOS VLSI designs」 | – | – | – | MOS VLSI タイミング検証・性能改善研究 |
| 1984 | 約26–30歳 | DEC Western Research Lab 入社 | – | – | – | – | マイクロプロセッサ設計・VLSI・メモリ階層研究 |
| 1984–1996 | 26–38歳 | Stanford University 非常勤教授 | – | – | – | – | VLSI設計・コンピュータアーキテクチャ講義 |
| 1990 | 約32–36歳 | ビクティムキャッシュ、ストリームプリフェッチ提案 | 論文:「Improving direct-mapped cache performance by the addition of a small fully-associative cache and prefetch buffers」 | – | – | – | 後のCPUキャッシュ設計に影響 |
| 1990年代 | 30代 | CACTI ツール開発 | CACTI: Cache & Memory Access / Timing / Area / Power モデル | – | – | – | メモリ階層設計評価ツールとして産業で広く採用 |
| 1994 | 36–40歳 | マルチプロセッサ / ストリームプリフェッチ関連特許 | US Patent 5,318,276 等 | – | – | – | キャッシュ最適化とプリフェッチ機構 |
| 2002 | 約40–45歳 | Compaq / HP Labs に移籍 | – | – | – | – | 高性能計算機・マルチコア設計・メモリ階層研究を継続 |
| 2005 | 約43–48歳 | HP Labs 内で論文・実装発表 | HP Labs Best Paper Award 受賞 | – | – | – | マルチコア・メモリ設計の実証 |
| 1993–現在 | 31–現在 | – | – | – | Jensen Huang、CEOとしてNVIDIAを牽引、GeForce / Tesla GPUシリーズ開発・HPC / AI向けGPU展開 | – | NVIDIA創業者の1人ではあるが、CEOとしてGPU事業拡大 |
| 2010年代前半 | 50代 | Google に移籍 | – | TPU 開発初期から設計に参画 | NVIDIAはCUDAエコシステム拡張、Tesla/P100開発 | – | AI向け専用ハードウェア研究開発 |
| 2014 | 約50–55歳 | Harry H. Goode Memorial Award 受賞 | – | TPU v1/v2 設計の技術的基盤に貢献 | NVIDIA Maxwell/ Pascal GPU世代でディープラーニング市場に進出 | – | コンピュータアーキテクチャ・メモリシステム分野での貢献 |
| 2015 | 約51–56歳 | Eckert–Mauchly Award 受賞 | – | TPU v2 発表・商用化 | NVIDIA Tesla P100 / Volta GPU 発表、AI向けTensorコア導入 | – | デジタルコンピュータアーキテクチャへの継続的貢献 |
| 2016–2017 | 55–57歳 | 論文・特許多数発表 | Jouppi et al., In-Datacenter Performance Analysis of a TPU, ISCA 2017 他 | TPU v2/v3 開発、SparseCore 初導入 | NVIDIA V100 / Volta GPU ディープラーニング学習向け | Gemini プロジェクト初期研究 | Google Gemini 開発準備段階 |
| 2018–2019 | 57–59歳 | – | Jouppi et al., TPU v3 アーキテクチャ論文 | TPU v3 クラスタ化、大規模分散学習対応 | NVIDIA Turing世代 / Tensorコア強化、AI推論向けGPU最適化 | Gemini 1.x モデルの研究・小規模実装 | LLM初期モデル設計・評価 |
| 2020–2021 | 59–61歳 | – | Jouppi et al., TPU v4 事例論文 | TPU v4 光通信インターコネクト、HBM統合 | NVIDIA A100 GPU / Ampere世代、AI学習クラスタ最適化 | Gemini 1.x / Gemini 2 開発 | 大規模LLM学習のためのTPU v4活用 |
| 2022 | 61–62歳 | – | – | TPU v4/v5 テスト運用開始、SparseCore最適化 | NVIDIA H100 / Hopper世代発表、低精度演算と大規模並列化 | Gemini 1.5 / 2.0 発表 | TPUクラスタを活用した大規模LLMの学習 |
| 2023 | 62–63歳 | – | – | TPU v5 さらに大規模化、メモリ・通信最適化 | NVIDIA H100 GPU 大規模クラスタ展開 | Gemini 3 発表、マルチモーダル対応 | LLM学習・推論にTPU v5を最大活用 |
| 2024 | 63–64歳 | Seymour Cray Computer Engineering Award 受賞 | – | TPU v5 実運用、クラウドAI学習最適化 | NVIDIA H100 / AIクラウドサービス統合 | Gemini 4 開発・運用 | Geminiシリーズの商用クラウド展開開始 |
| 2025 | 64–65歳 | – | – | TPU 次世代設計(チップレット・大規模分散・低精度演算)試験開始 | NVIDIA GPU チップレット化、AI向けハイブリッド運用 | Gemini 5 公開、TPU / GPU両方で最適化 | TPUとGPUの競争はさらに高度化、LLM向けハードウェア共進化時代 |
注記
- 年齢は概算です(正確な生年は非公開のため)。
- Google での TPU 関与は公開情報と推定を含む。
- CACTI ツールやキャッシュ研究など、学術論文・産業実装両面で影響力が大きい。
- TPU関連は公開情報・論文・特許情報を基に推定。
- NVIDIA列はジェンスン・フアンのCEOとしての戦略・製品開発・AI向けGPU導入を中心に整理。
- 2025年までの予測は技術トレンドと公開情報を基にした推定。
- この年表により Norman Jouppi の技術貢献と TPU 世代進化、GPU / Jensen Huang の戦略・技術進化を並列で理解可能。
- Google Gemini 列は、LLM(大規模言語モデル)開発の進化と TPU / GPU 活用の状況を反映。
- TPU と Gemini の連携、GPU クラスタでの学習など、AIハードウェアとモデルの共進化を並列で理解可能。

コメント
コメントを投稿